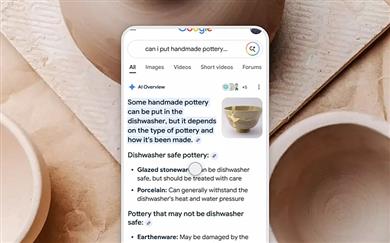
Medtem ko je spletno iskanje nekoč prikazovalo seznam modro označenih povezav do različnih virov, danes storitve, kot sta Google in specializirani iskalnik z umetno inteligenco Perplexity, vse pogosteje ponujajo že oblikovane povzetke odgovorov (»AI Overviews«). Čeprav se to uporabnikom zdi priročno, tak pristop vse bolj skrbi medijske nadzorne organe. Medijska ustanova Berlin-Brandenburg (mabb) ter Medijska ustanova Hamburg/Schleswig-Holstein (MA HSH) sta tako sredi januarja uvedli uradne upravne postopke proti obema tehnološkima podjetjema, s čemer je bil ustvarjen precedenčni primer, ki odpira vprašanje, ali in kako lahko algoritemsko generirani odgovori vplivajo na oblikovanje ali zoževanje javnega mnenja.
V središču preiskave je skrb za medijsko pluralnost. Če klepetalni sistemi združujejo informacije iz različnih virov v enoten, monoliten tekst, izvor informacij pogosto izgubi pomen. Vse več uporabnikov se namreč informira neposredno prek takšnih povzetkov.
Strah pred scenarijem »nič klikov«
Omenjeni organi želijo razjasniti, kdo nosi novinarsko in pravno odgovornost za vsebine, ki jih generira umetna inteligenca. Posebej pod drobnogledom je podjetje Perplexity, saj zunanje spletne strani obravnava predvsem kot opombe in ne kot samostojne ciljne vire. Tudi Google s svojimi pregledi, ustvarjenimi z umetno inteligenco, vse bolj prodira na ta trg. Na pametnih telefonih ti povzetki pogosto zapolnijo celoten vidni del zaslona in klasične rezultate iskanja potisnejo na spodnji, manj opazen del.
Ta trend krepi strah pred t. i. scenarijem »zero-click«, pri katerem uporabnik zaradi že pripravljenega odgovora nima več potrebe po obisku izvorne spletne strani. Prve študije nakazujejo znatne izgube dosega za založnike in ponudnike informacij.
Google zanika neposredno povezavo med uvedbo povzetkov AI Overviews in upadom števila klikov. Vendar se pravni pritisk stopnjuje. Deželno sodišče v Frankfurtu je nedavno odločilo, da napačnih navedb umetne inteligence ni mogoče obravnavati zgolj kot tehnično napako. Če umetna inteligenca razširja napačne informacije o podjetjih, je to lahko opredeljeno kot dejanje nelojalne konkurence. S tem prizadeta podjetja pridobijo pravno podlago za uveljavljanje prepovednih zahtevkov zoper t. i. halucinacije algoritmičnih sistemov.
Iskalniki kot super-uredništva?
Pravna podlaga za ukrepanje medijskih ustanov temelji poleg Medijskega državnega sporazuma tudi na evropski Uredbi o digitalnih storitvah (Digital Services Act – DSA). Ta velikim platformam nalaga obveznost, da vnaprej ocenijo in zmanjšajo sistemska tveganja za svobodo izražanja in medijski pluralizem. Google in Perplexity imata na voljo več tednov za podajo uradnega odgovora na očitke.
Ob tem se že kaže spor glede pristojnosti. Google postavlja pod vprašaj pristojnost nemških medijskih regulatorjev ter kot primarna sogovornika navaja Evropsko komisijo in irski organ za varstvo podatkov. Evropska komisija trenutno preiskuje tudi vprašanje, ali je Google pri uporabi umetne inteligence neupravičeno prevzemal tuje vsebine. Že oktobra so deželne medijske ustanove na podlagi strokovnega mnenja opozorile, da odgovori, ustvarjeni z umetno inteligenco, ustvarjajo nove vsebine in izpodrivajo uveljavljene informacijske vire. To ima daljnosežne posledice za vidnost novinarskih vsebin, financiranje medijev ter raznolikost informacij, dostopnih na spletu. Izguba spletnega prometa ogroža financiranje produkcije vsebin, ki je ključna za pluralno informacijsko okolje.
Ali bodo nemški regulatorji s svojim pristopom uspešni, bo odvisno predvsem od prihodnje razlage razmerja med nacionalnim medijskim pravom in evropsko regulacijo platform. Dosedanja svoboda eksperimentiranja z umetno inteligenco na račun založnikov je postavljena pod vprašaj. Postopki predstavljajo začetek razprave o tem, ali morajo iskalniki ostati nevtralni posredniki ali pa z ustvarjanjem lastnih vsebin postajajo nova oblika super-redakcij, ki zahteva strožji nadzor. ▪